
No Data Left Behind.
Security data is growing faster than traditional analytics models can handle. Even advanced pipelines strain at massive scale. It raises a real question: is centralizing everything still viable?

For years, IT teams looked at their systems like a night sky, counting servers, logs, and databases one by one. Just a few points of light. But what if those dots could connect? Suddenly, the patterns appear. The hidden relationships. The risks you never knew existed. The compliance gaps. Welcome to the universe of your enterprise data.

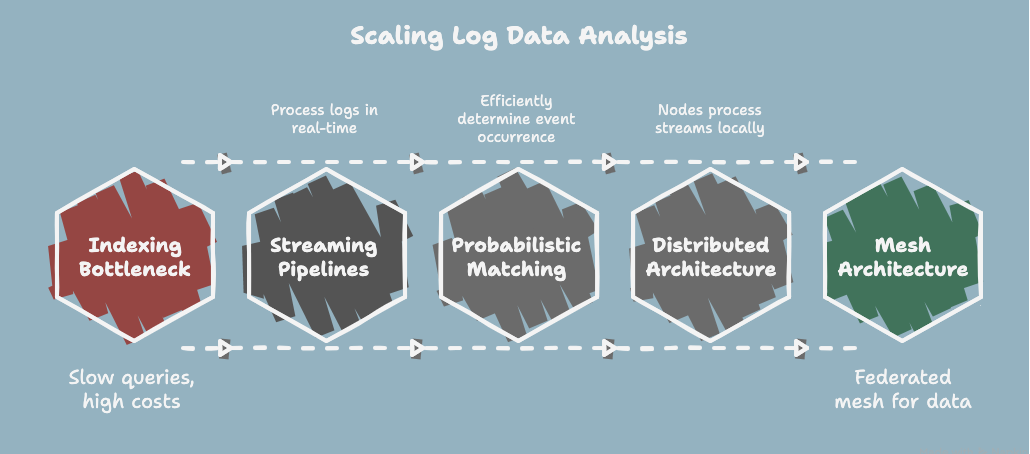
Most enterprises underestimate just how fast log data can grow. A typical index-based SIEM, think Elasticsearch, Splunk, or similar, works fine for hundreds of terabytes. You can search, correlate, and alert efficiently. But once you hit the mid-to-high hundreds of terabytes, you start seeing the limits: queries slow down, clusters require huge amounts of RAM, storage costs explode, and operational overhead becomes unmanageable. The indexes themselves become the bottleneck.
This is a mechanical limitation, not a theoretical one. Every indexed field consumes memory and CPU. In a system with billions of events per day, even minor increases in schema complexity or log volume multiply the load. Scale to petabytes, and most index-based engines simply can’t keep up. Clusters fail, queries time out, and alerts lag behind real-world events.
The Rise of Streaming and Probabilistic Search
So how do organizations handle petabyte-scale log data? The answer lies in a combination of streaming pipelines and probabilistic data structures.
Instead of fully indexing every log, modern systems use probabilistic matching, with techniques like Bloom filters, to efficiently determine whether a particular event or pattern has occurred. This reduces memory usage drastically while still providing high-confidence results. Coupled with streaming pipelines, logs can be ingested, processed, and correlated in real time without the need to store and index every single event immediately.
The architecture shifts from a monolithic architecture to a distributed architecture. Each node can process streams locally, perform probabilistic matching, and share summary results with other nodes. This enables enterprises to scale well beyond the hundreds of terabytes limit of traditional indexing, handling petabytes of data with near-real-time alerts, correlations, and compliance monitoring, all without waiting for an index rebuild.
When Scale Pushes Back
Even streaming and probabilistic engines have limits. At multi petabyte scale, network throughput, storage durability, and compute costs start to compound as we send data to a single cluster. Latency creeps in as the number of distributed nodes increases. And while you can trade off precision for scalability, you eventually hit diminishing returns.
The problem isn’t just compute. It’s coordination between an increasing number of processing nodes. The more you distribute, the harder it becomes to maintain global visibility and consistency without drowning in replication and synchronization overhead.
Enter the Mesh Era
This is where, Security Analytics Mesh(SAM), a federated mesh layer, aligned with the principles of Cybersecurity Mesh Architecture (CSMA), emerges as the next step in evolution. Instead of forcing all logs through a single analytics cluster, the mesh treats each component in the security ecosystem as a participant in a shared fabric.
Data doesn’t have to centralize. It can stay distributed, owned by the domain that generates it, while still being queryable and correlated across the mesh.
The result is not just scale, but resilience and context. A mesh layer makes it possible to:
Offload processing from individual engines by distributing responsibility across multiple data domains
Preserve local control and compliance while still enabling global visibility
Reduce bottlenecks by querying data where it lives rather than copying everything into a central store
SAM isn’t about chasing infinite scalability. It’s about acknowledging that centralization itself eventually becomes the problem. The mesh is the natural next stage of evolution.
The Next Evolution: From Index to Streaming to Mesh
When you step back, the progression becomes clear:
Index-based engines gave us structured search and correlation, but hit limits in the hundreds of terabytes.
Streaming and probabilistic systems extended those limits into the multi-petabyte range, but still carry mechanical constraints at extreme scale.
Federated mesh architectures move beyond centralization entirely—enabling interoperable systems that can scale, comply, and defend in unison.
The future of enterprise security data isn’t one massive monolithic SIEM trying to hold it all. It’s a mesh where each part of the ecosystem contributes its piece and the architecture stitches it together into something greater than the sum of its parts.
That’s the real meaning of no data left behind. Where every dataset stays in play, analyzed in place, governed in context, and ready when it matters most.